Google Hacking Techniques
By using the basic search techniques combined with Google's advanced operators, anyone can perform information-gathering and vulnerability-searching using Google. This technique is commonly referred to as Google hacking.
Site Mapping
To find every web page Google has crawled for a specific site, use the site: operator. Consider the following query:
site:http://www.microsoft.com microsoftThis query searches for the word microsoft, restricting the search to the http://www.microsoft.comweb site. How many pages on the Microsoft web server contain the word microsoft? According to Google, all of them! Google searches not only the content of a page, but the title and URL as well. The word microsoft appears in the URL of every page on http://www.microsoft.com. With a single query, an attacker gains a rundown of every web page on a site cached by Google.
There are some exceptions to this rule. If a link on the Microsoft web page points back to the IP address of the Microsoft web server, Google will cache that page as belonging to the IP address, not the http://www.microsoft.com web server. In this special case, an attacker would simply alter the query, replacing the word microsoft with the IP address(es) of the Microsoft web server.
Finding Directory Listings
Directory listings provide a list of files and directories in a browser window instead of the typical text-and graphics mix generally associated with web pages. These pages offer a great environment for deep information gathering (see Figure 1).
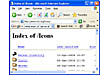 Figure 1 A typical directory listing.
Figure 1 A typical directory listing.Locating directory listings with Google is fairly straightforward. Figure 1 shows that most directory listings begin with the phrase Index of, which also shows in the title. An obvious query to find this type of page might be intitle:index.of, which may find pages with the term index of in the title of the document. Unfortunately, this query will return a large number of false positives, such as pages with the following titles:
- Index of Native American Resources on the Internet
- LibDex—Worldwide index of library catalogues
- Iowa State Entomology Index of Internet Resources
Judging from the titles of these documents, it's obvious that not only are these web pages intentional, they're also not the directory listings we're looking for. Several alternate queries provide more accurate results:
intitle:index.of "parent directory"
intitle:index.of name sizeThese queries indeed provide directory listings by not only focusing on index.of in the title, but on keywords often found inside directory listings, such as parent directory, name, and size. Obviously, this search can be combined with other searches to find files of directories located in directory listings.
Versioning: Obtaining the Web Server Software/Version
The exact version of the web server software running on a server is one piece of information an attacker needs before launching a successful attack against that web server. If an attacker connects directly to that web server, the HTTP (web) headers from that server can provide this essential information. It's possible, however, to retrieve similar information from Google's cache without ever connecting to the target server under investigation. One method involves using the information provided in a directory listing.
Figure 2 shows the bottom line of a typical directory listing. Notice that the directory listing includes the name of the server software as well as the version. An adept web administrator can fake this information, but often it's legitimate, allowing an attacker to determine what attacks may work against the server.
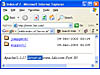 Figure 2 Directory listing server.at example.
Figure 2 Directory listing server.at example.This example was gathered using the following query:
intitle:index.of server.atThis query focuses on the term index of in the title and server at appearing at the bottom of the directory listing. This type of query can also be pointed at a particular web server:
intitle:index.of server.at site:aol.comThe result of this query indicates that gprojects.web.aol.com and vidup-r1.blue.aol.com both run Apache web servers.
It's also possible to determine the version of a web server based on default pages installed on that server. When a web server is installed, it generally will ship with a set of default web pages, like the Apache 1.2.6 page shown in Figure 3:
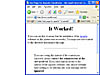 Figure 3 Apache test page.
Figure 3 Apache test page.These pages can make it easy for a site administrator to get a web server running. By providing a simple page to test, the administrator can simply connect to his own web server with a browser to validate that the web server was installed correctly. Some operating systems even come with web server software already installed. In this case, an Internet user may not even realize that a web server is running on his machine. This type of casual behavior on the part of an Internet user will lead an attacker to rightly assume that the web server is not well maintained, and by extension is insecure. By further extension, the attacker can assume that the entire operating system of the server may be vulnerable by virtue of poor maintenance.
The following table provides a brief rundown of some queries that can locate various default pages.
Apache Server Version | Query |
Apache 1.3.0–1.3.9 | Intitle:Test.Page.for.Apache It.worked! this.web.site! |
Apache 1.3.11–1.3.26 | Intitle:Test.Page.for.Apache seeing.this.instead |
Apache 2.0 | Intitle:Simple.page.for.Apache Apache.Hook.Functions |
Apache SSL/TLS | Intitle:test.page "Hey, it worked !" "SSL/TLS-aware" |
Many IIS servers | intitle:welcome.to intitle:internet IIS |
Unknown IIS server | intitle:"Under construction" "does not currently have" |
IIS 4.0 | intitle:welcome.to.IIS.4.0 |
IIS 4.0 | allintitle:Welcome to Windows NT 4.0 Option Pack |
IIS 4.0 | allintitle:Welcome to Internet Information Server |
IIS 5.0 | allintitle:Welcome to Windows 2000 Internet Services |
IIS 6.0 | allintitle:Welcome to Windows XP Server Internet Services |
Many Netscape servers | allintitle:Netscape Enterprise Server Home Page |
Unknown Netscape server | allintitle:Netscape FastTrack Server Home Page |
Using Google as a CGI Scanner
To accomplish its task, a CGI scanner must know what exactly to search for on a web server. Such scanners often utilize a data file filled with vulnerable files and directories like the one shown below:
/cgi-bin/cgiemail/uargg.txt
/random_banner/index.cgi
/random_banner/index.cgi
/cgi-bin/mailview.cgi
/cgi-bin/maillist.cgi
/cgi-bin/userreg.cgi
/iissamples/ISSamples/SQLQHit.asp
/iissamples/ISSamples/SQLQHit.asp
/SiteServer/admin/findvserver.asp
/scripts/cphost.dll
/cgi-bin/finger.cgiCombining a list like this one with a carefully crafted Google search, Google can be used as a CGI scanner. Each line can be broken down and used in either an index.of or inurl search to find vulnerable targets. For example, a Google search for this:
allinurl:/random_banner/index.cgireturns the results shown in Figure 4.
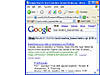 Figure 4 Sample search using a line from a CGI scanner.
Figure 4 Sample search using a line from a CGI scanner.A hacker can take sites returned from this Google search, apply a bit of hacker "magic," and eventually get the broken random_banner program to cough up any file on that web server, including the password file, as shown in Figure 5.
 Figure 5 Password file captured from a vulnerable site found using a Google search.
Figure 5 Password file captured from a vulnerable site found using a Google search.Note that actual exploitation of a found vulnerability crosses the ethical line, and is not considered mere web searching.
Of the many Google hacking techniques we've looked at, this technique is one of the best candidates for automation, because the CGI scanner vulnerability files can be very large. The gooscan tool, written by j0hnny, performs this and many other functions. Gooscan and automation are discussed below.
It's nice to see that some people still understand how to write a quality post! trig identitys
ReplyDeleteNice post! This is a very nice blog that I will definitively come back to more times this year! Thanks for informative post. how to install notepad plugins
ReplyDeleteI was on Twitter looking for Neiko Tools when I found a link to this blog, happy I stopped by – Cheers Jazz Internet Packages Details by Pkmobilereviews
ReplyDeletethank you for your interesting infomation. Zong All in One Internet Packages Details by Pkmobilereviews
ReplyDeletenice bLog! its interesting. thank you for sharing.... Jazz Internet Packages Details by Pkmobilereviews
ReplyDeleteI’m really thankful on the author of the post for producing this lovely and informative article live to put us. We actually appreciate ur effort. Maintain the great work. . . . Cosa Snap on Leather Wallet Cases
ReplyDeleteI like this post,And I guess that they having fun to read this post,they shall take a good site to make a information,thanks for sharing it to me. Best iphone leather Covers
ReplyDelete